How to recognize the texts?
This document explains how character recognition works in TopSolid'Inspection. It can be used as a response to reliability problems when retrieving dimensions and tolerances from a PDF or image drawing.
Types of files used
The method of retrieving characters in the drawing depends on the type of file being used.
- Image files (BMP, JPG, TIFF) are transformed into image PDF files.
- PDF files can be classified into three different types, depending on how the file was created:
- Image: corresponds to files resulting from document scanning. They only contain one image that takes up the entire page. The texts can only be recovered by a pixel recognition (OCR).
- Text (or digital): corresponds to files generated by a software such as CAD software. They contain texts and images integrated in the file using a vectorized method. The texts are accessible and searchable, the mouse cursor changes when hovering over the texts and it is possible to perform copy-and-paste operations. The text can be retrieved by reading the characters directly in the file. Please note that in a mixed file with texts and image characters, only the texts are processed.
- Image PDF: corresponds to files on which an OCR recognition process has added a searchable text layer. This type of file will be used by the software as an image file.
- DXF/DWG vector files are processed in two ways:
- Direct reading of the double-clicked value in the file. It is also possible to double-click on a drawing line.
- Reading via OCR on a traced area which can be assimilated to a recovery on an image.
 |
The type of file determines the ballooning technique, i.e. the gesture used to draw the frame around the value to be retrieved. |
Image-based operation
It is advisable to check the "Image File" box in the project characteristics when working with image-type drawings.

The OCR component used is a black box with very few parameters. It processes the small image generated during the ballooning process resulting in a character string.
The interpretation of the character string is done by the software which tries to find the dimension and the tolerances.
- The recognition process is not an exact science because it involves interpreting the pixels of an image without knowledge of the font. Handwritten, vertical, multi-line texts are difficult to recognize.
- The interpretation process can also fail to match human intelligence because it depends on the order of the words found and whether or not all the characters are present.
Example:
|
In the drawing: 38±0.2 Dimension: 38 |
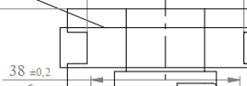 |
From version 7.17 onwards, when the "Image File" checkbox is active, the recovery window that appears during a ballooning operation can propose several OCR interpretation results.
| It's not necessarily the highest score that's closest to the right value. | 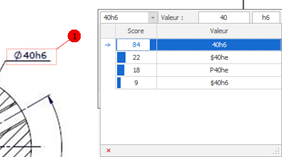 |
Tips and tricks :
How can I improve OCR recognition on image-based PDFs?
- Check that the "Image File" box is active.
- Drawing method for the frame: Try not to include pixels that would interfere with recognition.
- Very often the symbol Ø is not a true character but a graphic representation of the symbol. It cannot therefore be read as text.
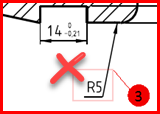

-
- Don't add characters that are unlikely to be recognized.


- Use the drop-down list to select the proposal closest to the target value.
- Reproduce the ballooning process with a different zoom level.
When OCR doesn't offer a choice, it's possible that the image recovered by drawing the frame is too small in terms of dimensions (pixels). Reducing the zoom level may result in better resolution. - Use the image management tools in the checkpoint details to orientate the image horizontally, sharpen image and then relaunch OCR recognition.
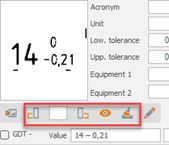
 |
Keep in mind that manual modification of the value and/or tolerances in the retrieval window or in the grid is often quicker than restarting OCR recognition. |
Notes:
- OCR recognition of text on two levels is unlikely to work properly.
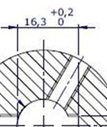
- OCR recognition on vertical text is less efficient. It is therefore preferable to rotate the layout before creating the checkpoint frame.

For obliquely oriented text, draw the frame and then use the rotation tools at the checkpoint detail.
- Trying to obtain better quality PDF drawings (text type PDF) is an improvement not to be neglected. With CAD software, it is sometimes sufficient to check a box in the settings or use another export menu to generate a text PDF instead of an image PDF.
|
CAD systems on the market have greatly improved the quality of exported PDF drawings. Asking your customers to change their habits slightly can save precious time in the inspection process. |
Text-based operation
The component used to read PDFs has its own text query system. The action of framing the dimension allows you to retrieve the coordinates of a rectangle in the PDF and the component is then asked to provide the resulting texts found at these coordinates.
The system is more reliable than OCR but there can also be failures that are related to the structure of the PDF file itself. Imagine a PDF file with lots of cells (like Excel) but with invisible cells that can be merged horizontally or vertically.
Each cell may contain texts, images or "empty".
Example:
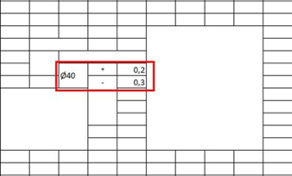 |
The red frame is what is seen on the screen, it includes the dimension, the "+" sign, the "-" sign and the tolerances. However, the API of the only component provides the "+0.2 Ø40 0.3" text. There is no "-" sign. Perhaps because in the coordinates of the rectangle, the box that contains the "-" sign is not complete. |
| With the "+0.2 Ø40 0.3" text, the interpreted result is false: | |
| Dimension: 38 Upper tolerance: 0.3 Lower tolerance: 0.2 |
PDF drawings are often of a mixed type. Some text is accessible, while others are images.
In this example, "8H7" is searchable text, while "Ø" is a graphic representation of the symbol.
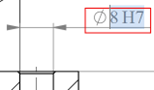
Tips and tricks:
How can I improve the capture of searchable text in text-based PDFs?
- The highlighted text is retrieved.
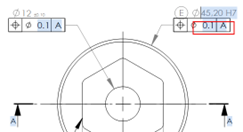
- Drawing method for the frame:
- Start the drag ballooning movement when the mouse cursor changes from "arrow" to "selection".

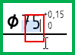
- Select highlighted text rather than the entire target value.
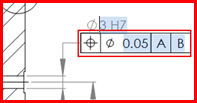
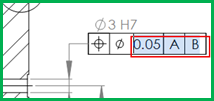
- Test different "frame directions".
The frame can be drawn from bottom to top or top to bottom, and from right to left or left to right.
The ESC key is used to interrupt a drawing and start again.
- Start the drag ballooning movement when the mouse cursor changes from "arrow" to "selection".
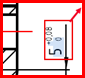 |
Dimension: 5 0 Upper tolerance: 0 Lower tolerance: 0 |
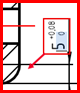 |
Dimension: 5 0 Upper tolerance: 0 Lower tolerance: 0 |
 |
Dimension: 5 Upper tolerance: 0.08 Lower tolerance: 0 |
- Retracing the frame a posteriori is one way of obtaining a good visual, but it is not mandatory. Use the "Redraw box" function in the checkpoint detail or in the Balloon remote control.

Notes:
- Image characters are not recovered.
- Enable the "Image File" checkbox in the project characteristics to force the use of OCR even on text-based PDF drawings. No attempt is then made to retrieve searchable text.
- Configuring acronyms with alternative acronyms can enable automatic entry of the acronym as soon as the value is retrieved.

Conclusion
Regardless of the type of file used, there are numerous possibilities for character interpretation, and it is impossible to foresee in advance all the scenarios that may be encountered.
These interpretation problems can be attributed to the limitations of the technologies currently used in the software.
Are they bugs? In any case, it currently seems impossible to correct/improve them.
Only a development/change of the OCR engine may perhaps make it possible to improve certain scenarios.
But for the moment there are no plans about it.