Comment reconnaitre les textes ?
Cet article explique le mode de fonctionnement de la reconnaissance de caractère dans TopSolid'Inspection. Il peut être apporté comme réponse à tous problèmes de fiabilité de récupération des dimensions et tolérances sur un plan PDF ou image.
Types de fichiers utilisés
La méthode de récupération des caractères dans le plan dépend du type de fichier utilisé.
- Les fichiers de type image (BMP, JPG, TIFF) sont transformés en fichier PDF de type image.
- Les fichiers au format PDF peuvent être classés en trois types différents, selon la façon dont le
fichier a été créé :
- Le type image correspond aux fichiers issus de la numérisation de document. Ils contiennent uniquement une image qui prend toute la page. Les textes ne peuvent être récupérés que par une reconnaissance des pixels (OCR).
- Le type texte (ou numérique) correspond aux fichiers générés par des logiciels tels que les logiciels de CAO. Ils contiennent des textes et des images intégrés dans le fichier de manière vectorisée. Les textes sont accessibles et interrogeables, le curseur de la souris se transforme en survolant les textes et il est possible d'effectuer des opérations de copier-coller. Le texte peut être récupéré par lecture des caractères directement dans le fichier.
A noter que dans un fichier mixte avec des textes et des caractères de type image, seuls les textes sont traités. - Le troisième type de fichier est un PDF de type image sur lequel un processus de reconnaissance OCR a rajouté une couche texte interrogeable. Ce type de fichier sera exploité par le logiciel comme un fichier de type image.
- Les fichiers vectoriels de type DXF, DWG sont traités de deux façons :
- Lecture directe dans le fichier de la valeur double-cliquée. Il est aussi possible de doublecliquer
sur un trait de plan. - Lecture via OCR sur une zone tracée qui peut être assimilée à une récupération sur une image.
- Lecture directe dans le fichier de la valeur double-cliquée. Il est aussi possible de doublecliquer
 |
Le type de fichier conditionne la façon de buller c'est-à-dire le geste à produirepour tracer le cadre autour de la valeur à récupérer. |
Fonctionnement sur type image
Il est conseillé de cocher la case "Image" dans les caractéristiques projet lorsque l'on travaille sur les plans de type image.
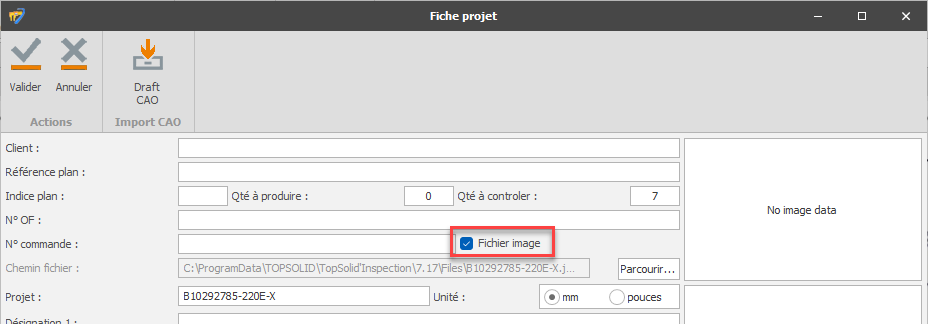
Le composant OCR utilisé est une boite noire très peu paramétrable. Il traite la petite image générée lors du bullage et retourne une chaîne de caractère.
L'interprétation de la chaîne de caractère est effectuée par le logiciel qui essaye de retrouver la cote et les tolérances.
- Le processus de reconnaissance n'est pas une science exacte car il s'agit d'interpréter les pixels d'une image sans connaissance de la police de caractère. Les textes manuscrits, verticaux, sur plusieurs lignes sont difficilement reconnus.
- Le processus d'interprétation peut aussi avoir des ratés par rapport à l'intelligence humaine car il dépend de l'ordre des mots trouvés et de la présence ou non de tous les caractères.
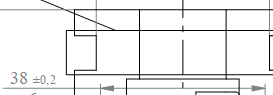
| Exemple : Dans le plan : 38±0.2 Si le signe « ± » n'est pas reconnu, le résultat est faux : Dimension : 38 Tolérance supérieure : 0,2 Tolérance inférieure : 0 |
 |
A partir de la version 7.17, lorsque la case "Image" est active, la fenêtre de récupération qui apparait lors d'un bullage peut proposer plusieurs résultats d'interprétation de l'OCR.
| Ce n'est pas forcément le score le plus élevé qui se rapproche le plus de la bonne valeur. |  |
Conseils et astuces :
Comment améliorer la reconnaissance OCR sur les PDF de type image ?
-
-
- Vérifier si la case "Image" est active.
- Méthode de tracé pour le cadre :
- Essayer de ne pas inclure des pixels qui parasiteraient la reconnaissance.
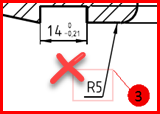

- Ne pas ajouter des caractères qui ont peu de chance d'être reconnus.


- Essayer de ne pas inclure des pixels qui parasiteraient la reconnaissance.
- Utiliser la liste déroulante pour choisir la proposition se rapprochant le plus de la valeur ciblée.
- Reproduire le bullage avec un niveau de zoom différent. Lorsque l'OCR ne propose aucun choix, il est possible que l'image récupérée par le tracé du cadre soit trop petite en termes de dimensions (pixels). Réduire le niveau de zoom peut apporter une meilleure résolution.
- Utiliser les outils de gestion de l'image dans le détail du point de contrôle pour orienter horizontalement l'image, renforcer les pixels puis relancer la reconnaissance OCR.

-
|
Il faut garder à l'esprit que la modification manuelle de la valeur et/ou des tolérances dans la fenêtre de récupération ou dans la grille est souvent plus rapide que de relancer la reconnaissance OCR. |
Remarques :
-
-
- La reconnaissance OCR des textes sur deux niveaux n'a que peu de chance de fonctionner correctement.

- La reconnaissance OCR sur des textes verticaux est moins performante. Il est donc préférable de tourner le plan avant de créer le rectangle du point de contrôle.


Pour les textes orientés en oblique, tracer le cadre puis utiliser les outils de rotation au niveau du détail du point de contrôle. - Essayer d'obtenir des plans PDF de meilleure qualité (PDF de type texte) est une voie d'amélioration à ne pas négliger. Au niveau des logiciels CAO, il suffit parfois de cocher une case dans le paramétrage ou d'utiliser un autre menu d'export pour qu'ils génèrent un PDF de type texte à la place d'un type image.
- La reconnaissance OCR des textes sur deux niveaux n'a que peu de chance de fonctionner correctement.
-
|
Les logiciels de CAO du marché ont grandement amélioré la qualité des plans PDF exportés. Demander à ses clients de changer légèrement ses habitudes peut faire gagner un temps précieux dans le processus de contrôle. |
Fonctionnement sur type texte
Le composant utilisé pour la lecture des PDF possède son propre système d'interrogation des textes. L'action d'encadrer la cote permet de récupérer les coordonnées d'un rectangle dans le PDF et il est ensuite demandé au composant de retourner les textes trouvés à ces coordonnées. Le système est plus fiable que l'OCR mais il peut aussi y avoir des ratés qui sont liés à la structure même du fichier PDF.
Il faut imaginer un fichier PDF composé de pleins de cases (un peu comme Excel) mais avec des cellules invisibles qui peuvent être fusionnées horizontalement ou verticalement. Chaque cellule contient des textes, des images ou du "vide".
Exemple :
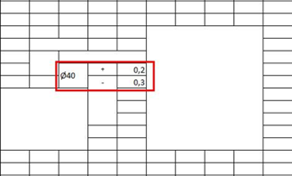 |
Le cadre rouge est ce que je vois à l'écran, il englobe bien la cote, le signe "+", le signe "-" et les tolérances. Or, l'API du composant me renvoie uniquement le texte « +0,2 Ø40 0,3 » Il n'y a pas le signe "-". Peut-être parce que dans les coordonnées du rectangle, la case qui contient le signe "-" n'est pas complète. |
Avec le texte « +0,2 Ø40 0,3 », le résultat interprété est faux :
Dimension : Ø40
Tolérance supérieure : 0,3
Tolérance inférieure : 0,2
Il arrive couramment que les plans PDF soient de type mixte. Certains textes sont accessibles et d'autres sont des images.
Dans cet exemple, "8H7" est du texte interrogeable alors que le sigle "Ø" est une représentation graphique du symbole.
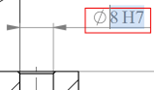
Conseils et astuces :
Comment améliorer la capture des textes interrogeables sur les PDF de type texte ?
- C'est le texte en surbrillance qui est récupéré.
- Méthode de tracé pour le cadre :
- Commencer le cliquer/déplacer de bullage lorsque le curseur de la souris se transforme de "flèche" à "sélection".
- Privilégier la sélection des textes en surbrillance plutôt que la totalité de la valeur ciblée.

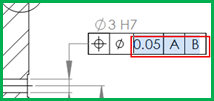
- Tester différents "sens de bullage".
Le cadre peut être tracé de bas en haut ou de haut en bas, et, de droite à gauche ou de gauche à droite.
La touche ECHAP permet d'interrompre un tracé pour recommencer.
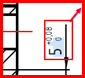
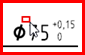
Dimension : 5 0
Tolérance supérieure : 0
Tolérance inférieure : 0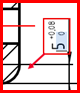
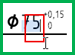
Dimension : 5 0
Tolérance supérieure : 0
Tolérance inférieure : 0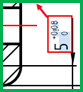
Dimension : 5
Tolérance supérieure : 0.08
Tolérance inférieure : 0
- Commencer le cliquer/déplacer de bullage lorsque le curseur de la souris se transforme de "flèche" à "sélection".
- Retracer le cadre à postériori est une solution pour obtenir un bon visuel, mais ceci n'est pas obligatoire.
Utiliser la fonction "Retracer le cadre" au niveau du détail du point de contrôle ou dans la télécommande à bulle.
Remarques :
- Les caractères en image ne sont pas récupérés.
- Activer la coche "Image" dans les caractéristiques projet permet de forcer l'utilisation de l'OCR même sur les plans PDF de type texte. Il n'y a alors pas de tentative de récupération des textes interrogeables.
- Paramétrer les Sigles avec des sigles alternatifs peut permettre la saisie automatique du Sigle dès la récupération de la valeur.

Conclusion
Indépendamment du type de fichier utilisé, les possibilités d'interprétation des caractères sont nombreuses et il est impossible de prévoir à l'avance tous les cas de figure rencontrés.
Ces problèmes d'interprétation peuvent être attribués aux limitations des technologies actuellement utilisées dans le logiciel.
Sont-ils des bugs ?
Dans tous les cas, il parait aujourd'hui impossible de les corriger.
Une évolution future du moteur OCR pourra peut-être permettre d’améliorer certains cas.
Mais pour l'instant, rien n'est prévu à ce sujet.